
Revisiting Microarchitectural Side-Channels
Date:
This talks presents the results of applying cache side-channels to contemporary hardware and investigating AES lookup tables, AES key scheduling, and Argon2. The slides give a brief overview of the content described in this blog post
Highlights
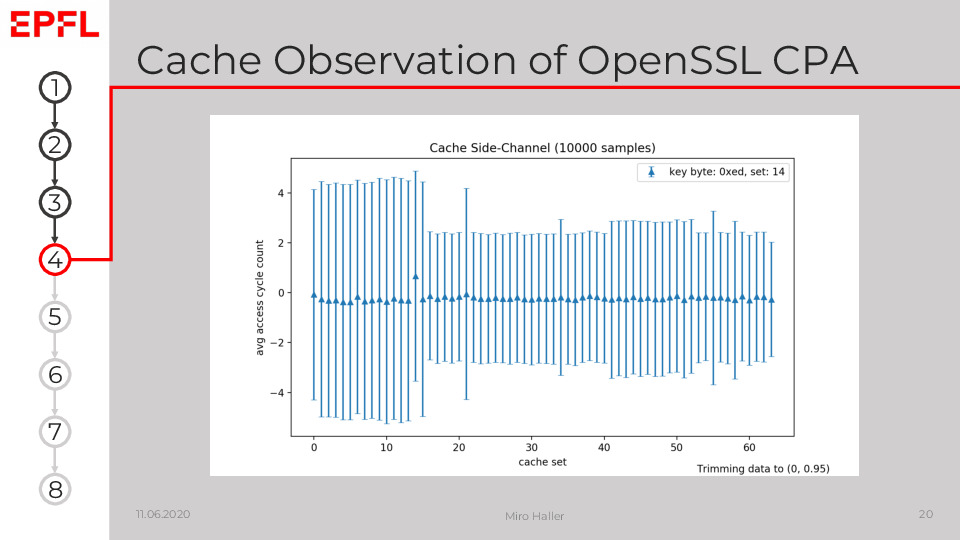
This plot shows that we are able to measure accessed cache sets on a Dell Latitude E6430 with Ivy Bridge processors (Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz) running Ubuntu 18.04. Set 14 is clearly slower than all other sets. This is leaked by AES lookup table accesses, which depend on the left four bits of the index key byte: 0xe of the key byte 0xed is equal to 14.

L2 caches are attractive targets because they are larger than L1 caches and cache misses have a higher penalty than L1 cache accesses. However, they did not receive much attention so far, because it is difficult for an adversary to build the data structure needed for Prime+Probe attacks due to the physical indexing.
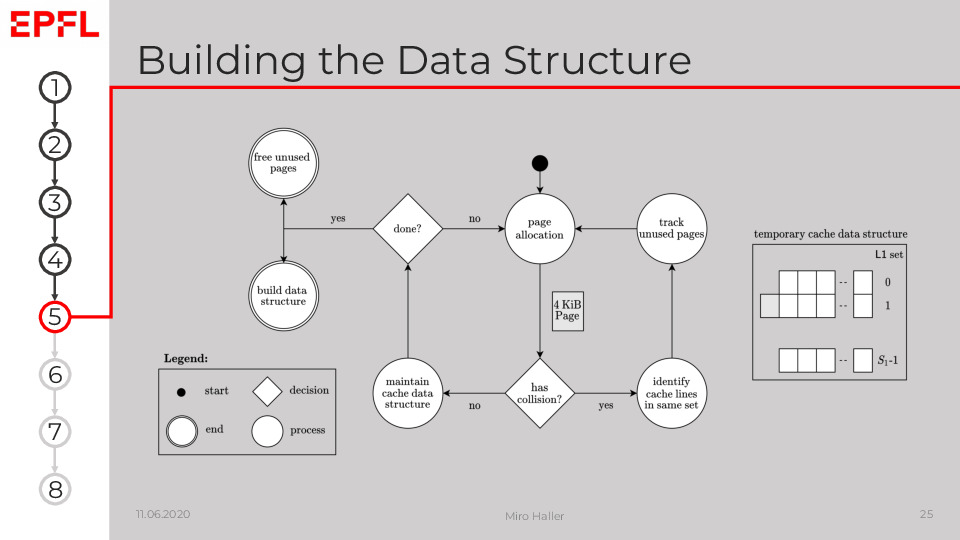
Both the unprivileged and privileged approach of CacheSC to build a Prime+Probe data structure for physically indexed caches follow the high-level procedure shown on the slide.
The main idea is to allocate memory pages, and then detect whether or not the cache lines covered by those pages should be included in our data structure. If we still did not fill a cache set, we add all cache lines of the page to a temporary cache data structure and continue allocating pages until this data structure fills L2. The collision detection and how we can identify cache lines in the same sets depends on the available privileges:
- A privileged attacker can use the pagemap interface exported by the kernel to translate virtual to physical addresses. The attacker simply counts how many cache lines are in which physical set and uses this to decide whether or not to add a newly allocated page to the data structure. However, this translation requires the CAP SYS ADMIN capability since Linux 4.0.
- The unprivileged version is more challenging to implement. We maintain a linked list of cache lines that map to the same L1 set, which we know from the virtual address. However, we do not know the exact L2 set of those cache lines as we miss the bits from the Physical Page Number (PPN). Then, we append the cache lines of a newly allocated page tentatively to their respective L1 set list in our temporary data structure. Next, we use Prime+Probe to detect collisions in L2. If we have more cache lines than ways in the same set in L2, they evict one cache line from this L2 set during the Prime phases, and we can measure an access time of L3 during Probe. The challenge in practice is to make this detection reliable. Assuming we identified a collision, we can use it to find the other cache lines in the same set in L2, by testing which cache lines in the temporary structure cause the collision.
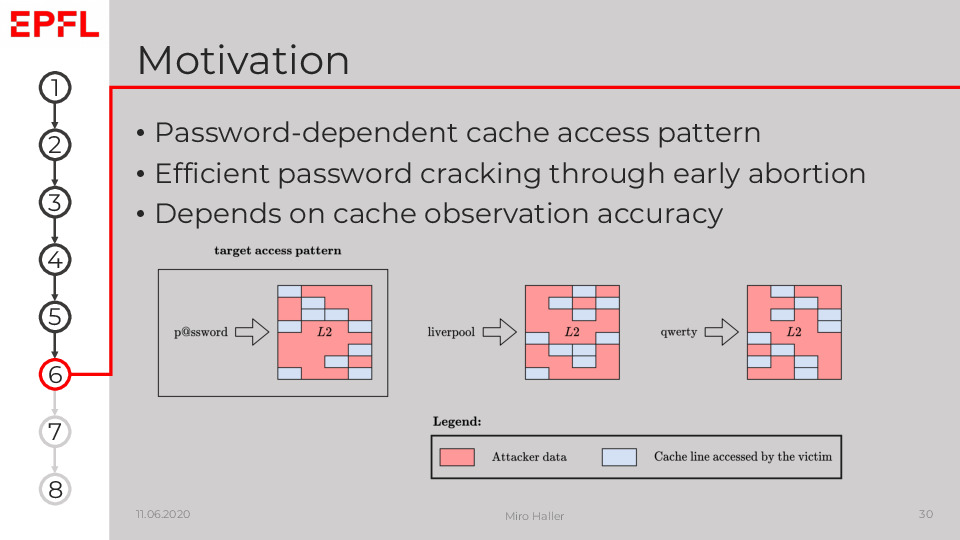
Our motivation to look at the memory-hard Argon2 was that if we can distinguish passwords from their cache access patterns, we might be able to abort the expensive Argon2 early and thus improve the efficiency of password crackers.
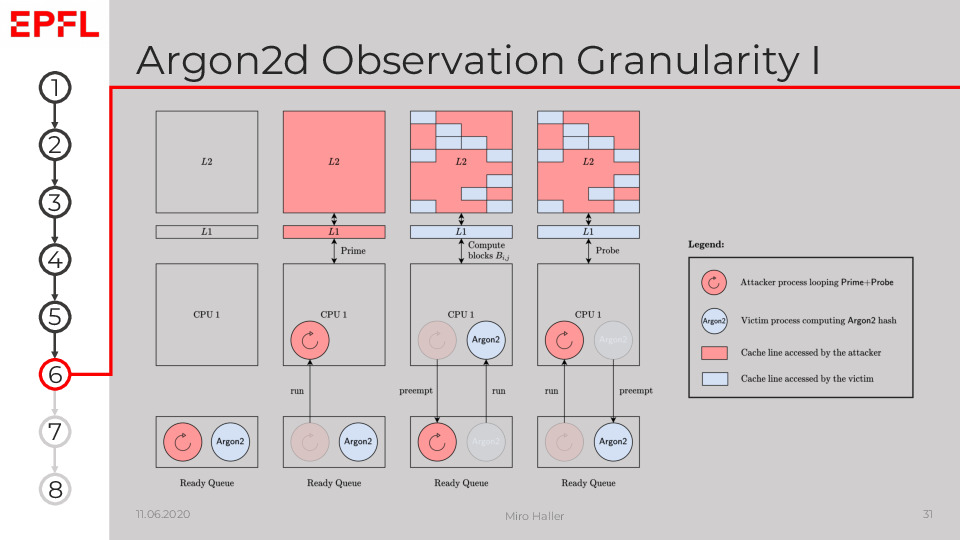
In this figure, we consider two processes, an attacker and a victim, running on the same CPU core. The attacker process A asynchronously performs many iterations of Prime+Probe, while the victim process V concurrently calculates an Argon2 hash. The plot visualises how this scenario depends on the scheduler:
Both processes are ready to execute. Ideally,
Ais already running beforeVto measure the first Argon2 block accesses.The scheduler allows
Ato execute, andAfills the caches with its data by performing iterations of Prime+Probe.The scheduler preempts
Aand runsVinstead.VaccessesCblocks during Argon2’s internal passes through memory. The referenced Argon2 blocks create an access pattern depending on the current block and therefore ultimately on the hashed password in Argon2d.The scheduler interrupts
Vand schedulesAagain.Acontinues to execute Prime+Probe and can observe the block access pattern ofVduring the first Probe phase.This procedure is repeated from point 2 until
Vfinishes its computation and terminates.
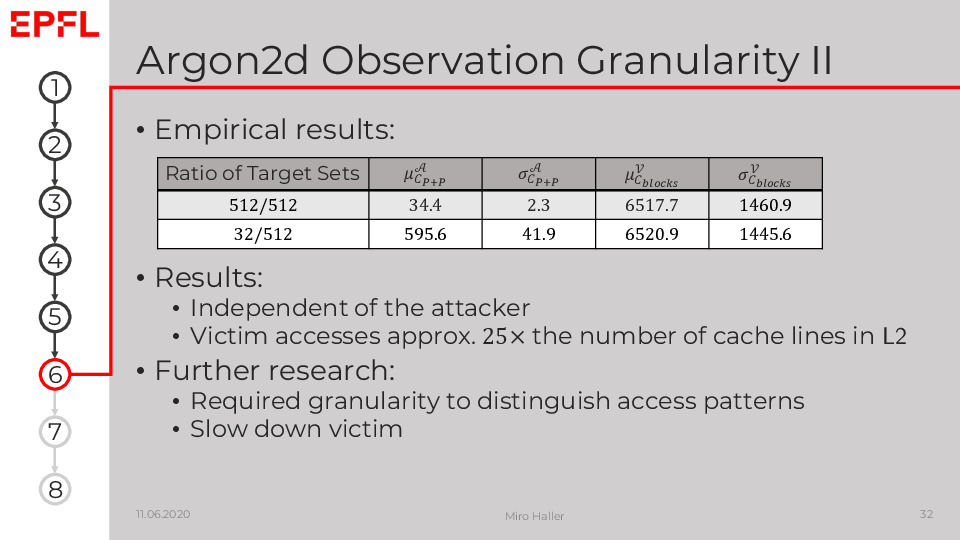
We found that the side-channel granularity is currently too coarse to measure significant patterns of Agon2. However, further research could make this attack practical by slowing down the victim of making the attack more fine granular.